Creating & Managing Pipelines
This guide walks you through creating a log pipeline from scratch and covers best practices for combining rules effectively.
Creating a Pipeline
-
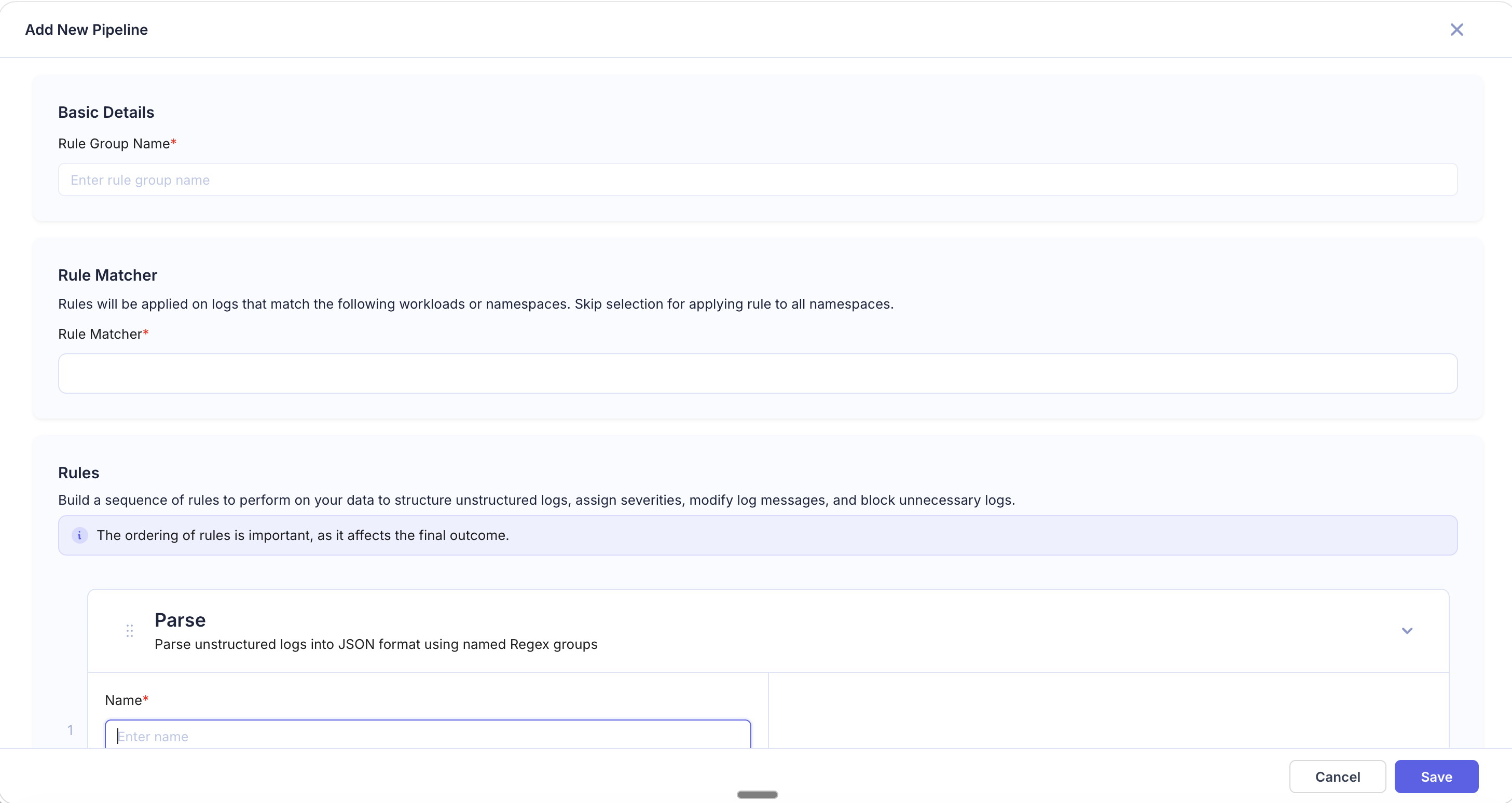
Navigate to Logs > Log Pipelines and click Add Pipeline in the top right.
-
Basic Details — Enter a Rule Group Name that describes the pipeline's purpose (e.g.,
redact-pii-api-gateway,parse-nginx-logs). -
Rule Matcher — Define which logs this pipeline applies to:
- Enter a workload or namespace pattern (e.g.,
us-2/log-printer/*,prod/api-gateway/*) - Use
*wildcards to match multiple workloads within a namespace - Skip the selection to apply the pipeline to all namespaces
- Enter a workload or namespace pattern (e.g.,
-
Add Rules — Click + Add Rule and choose a rule type. Configure the rule fields, then repeat to add more rules as needed.
-
Reorder Rules — Drag rules to change their execution order. Rules run top-to-bottom, and each rule operates on the output of the previous one.
-
Preview — The right panel shows how the rules affect your logs. Use this to validate behavior before saving.
-
Click Save to activate the pipeline.
Editing a Pipeline
Click on any pipeline in the list to open it for editing. You can:
- Modify existing rules or their configuration
- Add new rules or remove existing ones
- Reorder rules by dragging
- Update the Rule Matcher to target different workloads
Click Save to apply changes. Updated pipelines take effect on newly ingested logs.
Rule Ordering Best Practices
Since rules execute sequentially, the order you place them in matters:
- Parse first — If your logs are unstructured, place Parse rules at the top so subsequent rules can operate on the extracted fields.
- Extract and enrich next — Extract, JSON Extract, Add Field, and Timestamp Extract rules work best after the log has been structured.
- Replace before Block — Redact sensitive data before deciding whether to drop a log, so even blocked logs have their PII removed during the processing window.
- Block last — Place Block rules toward the end so they evaluate against the fully processed log.
- Remove Fields at the end — Strip unwanted fields as the final step, after all other transformations are complete.
Recommended order:
Parse → Extract / JSON Extract → Timestamp Extract → Add Field → Replace → Block → Remove FieldsCommon Pipeline Patterns
Structuring and Enriching Application Logs
Goal: Parse unstructured Node.js logs and tag with team ownership.
| Order | Rule Type | Configuration |
|---|---|---|
| 1 | Parse | Regex: \[(?P<level>\w+)\] (?P<timestamp>[\d\-T:\.Z]+) (?P<message>.+) |
| 2 | Timestamp Extract | Source Field: timestamp, Format: 2006-01-02T15:04:05.000Z |
| 3 | Add Field | New Field: team, Value: backend |
| 4 | Remove Fields | Exclude: raw_stacktrace |
PII Redaction Pipeline
Goal: Ensure no personally identifiable information is stored in logs. The example below shows a "Redact-PII" pipeline scoped to cluster-1/node-plum/* with a Replace rule that masks phone numbers using a regex pattern.
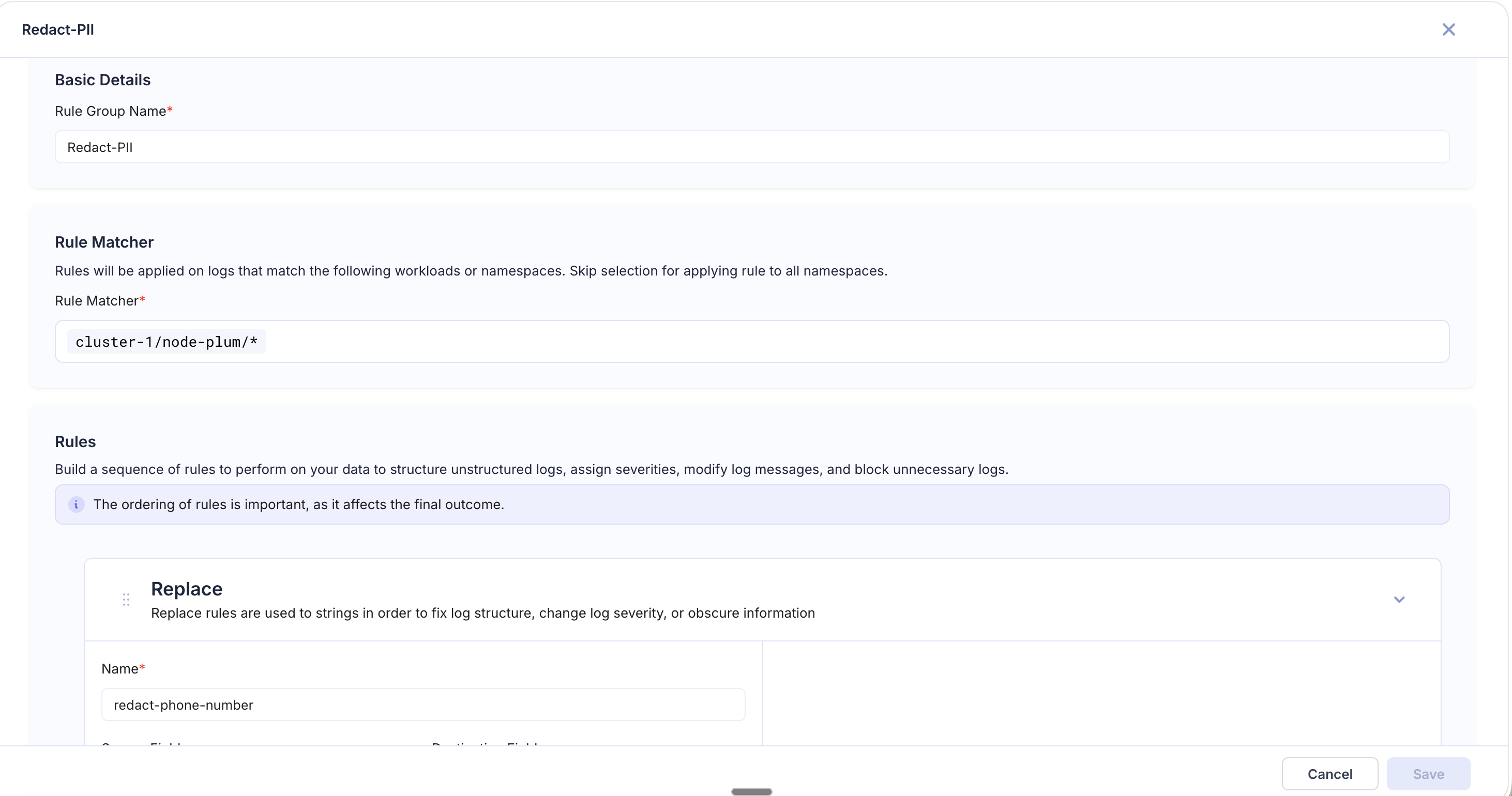
| Order | Rule Type | Configuration |
|---|---|---|
| 1 | Replace | Regex: \S+@\S+\.\S+ → [EMAIL_REDACTED] |
| 2 | Replace | Regex: \d{3}-\d{3}-\d{4} → [PHONE_REDACTED] |
| 3 | Replace | Regex: \d{4}[- ]?\d{4}[- ]?\d{4}[- ]?\d{4} → [CC_REDACTED] |
| 4 | Replace | Regex: api_key=\S+ → api_key=[REDACTED] |
Noise Reduction Pipeline
Goal: Cut log volume and costs by filtering out low-value logs.
| Order | Rule Type | Configuration |
|---|---|---|
| 1 | Block | Regex: GET /healthz|GET /readyz, Logic: Block all matching |
| 2 | Block | Source: severity, Regex: DEBUG|TRACE, Logic: Block all matching |
| 3 | Remove Fields | Exclude: x-request-headers, raw_body |
JSON Log Enrichment Pipeline
Goal: Extract key fields from structured JSON logs and add routing metadata.
| Order | Rule Type | Configuration |
|---|---|---|
| 1 | JSON Extract | Json Key: context.userId, Destination: user_id |
| 2 | JSON Extract | Json Key: error.code, Destination: error_code |
| 3 | Add Field | Regex: ERROR|FATAL on level, New Field: pagerduty_route, Value: critical |
| 4 | Remove Fields | Exclude: context.internalDebug |